AWK ist ein mächtiges Werkzeug in der Welt von Linux, das oft übersehen wird. Mit AWK Linux können wir Textdateien effizient bearbeiten und analysieren. Egal ob wir Daten filtern, Muster suchen oder Berichte erstellen möchten, AWK bietet uns eine flexible Lösung, die sich leicht an unsere Bedürfnisse anpassen lässt.
In diesem Artikel werden wir die Grundlagen von AWK näher beleuchten und die vielfältigen Anwendungen im Bereich der Textbearbeitung erkunden. Wir zeigen auf wie einfach es ist mit wenigen Zeilen Code komplexe Aufgaben zu erledigen. Unsere Reise durch die Funktionen und Möglichkeiten von AWK wird Ihnen helfen Ihre Produktivität erheblich zu steigern.
Sind Sie bereit mehr über AWK Linux zu erfahren und Ihr Wissen in der Textbearbeitung zu erweitern? Lassen Sie uns gemeinsam eintauchen in diese faszinierende Welt!
AWK Linux: Eine Einführung in die Textbearbeitung
Die Verwendung von AWK in Linux ermöglicht eine effiziente und leistungsstarke Textbearbeitung, die für verschiedene Anwendungen genutzt werden kann. Mit seiner Fähigkeit, Muster zu erkennen und Daten zu verarbeiten, ist AWK ein unverzichtbares Werkzeug für Programmierer, Systemadministratoren und jeden, der regelmäßig mit Textdateien arbeitet. In dieser Einführung möchten wir die Grundzüge von AWK erläutern und seine Bedeutung im Bereich der Textverarbeitung hervorheben.
Funktionen und Merkmale von AWK
AWK bietet zahlreiche Funktionen, die es uns ermöglichen, Texte auf unterschiedliche Weise zu bearbeiten:
- Mustererkennung: Wir können spezifische Muster in unseren Daten identifizieren und darauf basierende Aktionen durchführen.
- Datenmanipulation: AWK erlaubt es uns, Daten zu filtern, neu anzuordnen oder sogar berechnete Werte hinzuzufügen.
- Berichterstattung: Mit den integrierten Funktionen zur Formatierung können wir aussagekräftige Berichte aus unseren Daten generieren.
Ein Beispiel für eine einfache Anwendung könnte das Filtern einer Log-Datei nach bestimmten Ereignissen sein. So könnten wir alle Zeilen extrahieren, die einen kritischen Fehler anzeigen.
Syntax-Grundlagen
Die grundlegende Syntax von AWK folgt dem Format awk 'Bedingung {Aktion}'. Hierbei definieren wir zunächst eine Bedingung (zum Beispiel ein bestimmtes Muster) und legen dann fest, welche Aktion ausgeführt werden soll. Diese Struktur ermöglicht es uns, sehr präzise Anweisungen zur Verarbeitung unserer Texte zu formulieren.
Um unsere Kenntnisse weiter auszubauen, sollten wir uns auch mit den verschiedenen Variablen befassen:
- $0: Die gesamte Zeile
- $1, $2, …: Einzelne Felder innerhalb der Zeile
Diese Variablen sind entscheidend für die Manipulation der gewünschten Informationen in einem Datensatz.
| Feld | Bedeutung |
|---|---|
| $0 | Die gesamte Eingabezeile |
| $1 | Das erste Feld der Eingabezeile |
| $2 | Das zweite Feld der Eingabezeile |
Durch das Verständnis dieser Grundlagen sind wir gut gerüstet für komplexere Aufgabenstellungen in der Textbearbeitung mit AWK.
Die Grundlagen von AWK und seine Syntax
Die Grundlagen von AWK sind entscheidend, um die Leistungsfähigkeit dieses Tools in der Textbearbeitung mit Linux zu verstehen. AWK basiert auf einem einfachen, aber effektiven Konzept: Es verarbeitet Textdaten zeilenweise und führt je nach definierten Bedingungen spezifische Aktionen durch. Diese Flexibilität macht es zu einem bevorzugten Werkzeug für viele Nutzer, die mit strukturierten oder unstrukturierten Daten arbeiten.
Wichtige Syntax-Elemente
Die grundlegende Syntax von AWK ist einfach und intuitiv. Sie folgt dem Format awk 'Bedingung {Aktion}', wobei wir eine Bedingung angeben und festlegen, welche Aktion bei Erfüllung dieser Bedingung ausgeführt werden soll. Ein typisches Beispiel hierfür könnte sein:
awk '$1 == "Fehler" {print $0}' logfile.txtIn diesem Beispiel wird jede Zeile aus der Datei logfile.txt ausgegeben, wenn das erste Feld den Wert „Fehler“ hat.
Nützliche Variablen in AWK
Aber nicht nur die Grundstruktur ist wichtig; auch die Verwendung von Variablen spielt eine zentrale Rolle in der Arbeit mit AWK unter Linux. Zu den häufigsten Variablen gehören:
- $0: Die gesamte Zeile der Eingabe.
- $1, $2, …: Repräsentieren einzelne Felder innerhalb einer Zeile.
- NR: Die aktuelle Zeilennummer des Eingabestroms.
- NF: Die Anzahl der Felder in der aktuellen Zeile.
Dank dieser Variablen können wir gezielt Informationen extrahieren und manipulieren. Zum Beispiel ermöglicht uns die Kombination von $NF, das letzte Feld einer Zeile auszuwählen, was besonders nützlich sein kann bei variabel strukturierten Daten.
| Variable | Bedeutung |
|---|---|
| $0 | Ganze Eingabezeile anzeigen. |
| $1 – $N (z.B., $2) | Spezifische Felder innerhalb der Zeile darstellen. |
| NNR (Number of Records) | Zählt die bearbeiteten Datensätze/Zeilen. |
| Nf (Number of Fields) | Anzahl der Felder im aktuellen Datensatz angeben. |
Mithilfe dieser Grundlagen legen wir das Fundament für komplexere Operationen und Anwendungen im Bereich der Textbearbeitung mit AWK. So sind wir bestens gerüstet, um leistungsstarke Skripte zu schreiben und unsere Daten effizient zu bearbeiten.
Praktische Anwendungen von AWK in der Datenverarbeitung
Die praktischen Anwendungen von AWK in der Datenverarbeitung sind vielfältig und reichen von einfachen Datenextraktionen bis hin zu komplexen Analysen. In unserem täglichen Umgang mit Textdaten können wir AWK nutzen, um bestimmte Muster zu finden, Daten zu transformieren oder Berichte zu erstellen. Die Effizienz dieses Tools zeigt sich besonders bei großen Datensätzen, wo manuelle Bearbeitung nicht nur zeitaufwendig, sondern auch fehleranfällig wäre.
Datenanalyse und -filterung
Ein häufiges Szenario ist die Analyse von Log-Dateien oder CSV-Daten. Mit awk linux können wir gezielt Informationen extrahieren und filtern. Ein Beispiel für eine einfache Filteroperation könnte so aussehen:
awk -F',' '$3 > 100 {print $1, $2}' daten.csvIn diesem Fall wird aus einer CSV-Datei nur die erste und zweite Spalte ausgegeben, wenn der Wert in der dritten Spalte größer als 100 ist. Solche Abfragen sind mit AWK schnell erledigt und bieten uns sofortige Einblicke in unsere Daten.
Berichterstellung
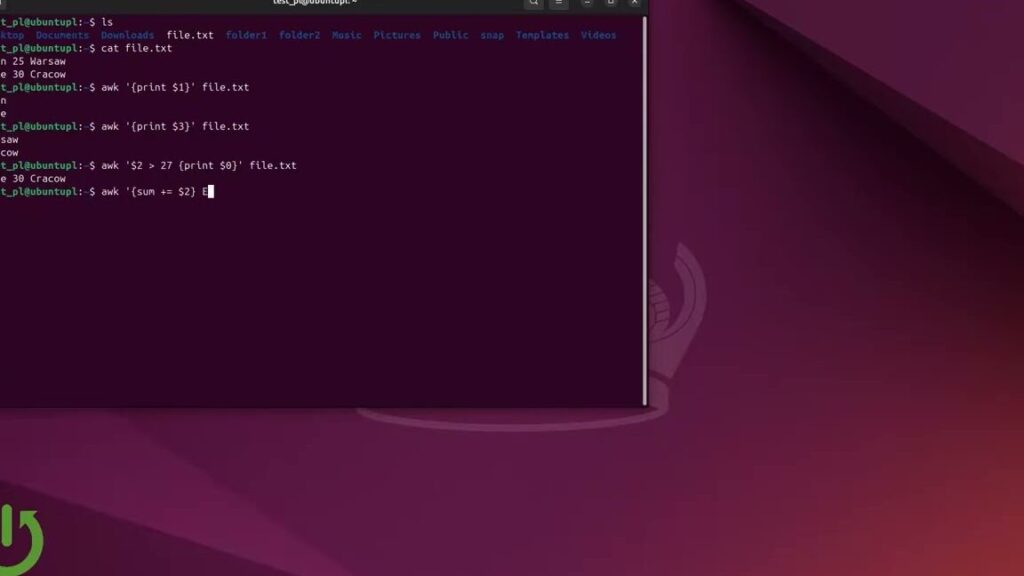
Aber nicht nur das Filtern von Informationen ist möglich; auch die Erstellung von Berichten gestaltet sich mit AWK einfach und effektiv. Zum Beispiel kann man Summen oder Durchschnittswerte berechnen:
awk '{sum += $2} END {print "Durchschnitt:", sum/NR}' daten.txtHier summieren wir sämtliche Werte der zweiten Spalte aus einer Datei und berechnen den Durchschnitt am Ende des Prozesses. Diese Technik ist besonders nützlich für Finanzdaten oder andere numerische Datensätze.
| Anwendung | Bedeutung |
|---|---|
| Datenanalyse | Schnelles Filtern und Extrahieren relevanter Informationen aus großen Datensätzen. |
| Berichterstellung | Kreation automatisierter Berichte durch Berechnung von Summen oder Durchschnittswerten. |
| Datenformatierung | Anpassung des Formats zur besseren Lesbarkeit oder Weiterverarbeitung durch andere Programme. |
Zudem ermöglicht AWK auch eine einfache Formatierung der Ausgabe. Oftmals möchten wir die Ergebnisse nicht nur sehen, sondern sie auch gut lesbar präsentieren oder für weitere Verarbeitung aufbereiten. Dies erreichen wir durch Anpassungen in unseren Skripten, sodass sie genau den Anforderungen entsprechen.
Mithilfe dieser praktischen Anwendungen können wir unser Wissen über AWK erweitern und effizientere Arbeitsabläufe im Bereich der Datenverarbeitung entwickeln. So wird deutlich, dass es ein unverzichtbares Werkzeug für jeden Nutzer ist, der regelmäßig mit textbasierten Informationen arbeitet.
Erweiterte Funktionen und Möglichkeiten von AWK
Nachdem wir die praktischen Anwendungen von AWK in der Datenverarbeitung untersucht haben, schauen wir uns nun die erweiterten Funktionen und Möglichkeiten an, die dieses mächtige Werkzeug bietet. awk linux ist nicht nur für grundlegende Aufgaben geeignet; es ermöglicht auch komplexe Operationen wie das Bearbeiten mehrerer Dateien gleichzeitig, das Erstellen benutzerdefinierter Funktionen und die Verarbeitung von Datenströmen in Echtzeit. Diese erweiterten Funktionen machen AWK zu einem unverzichtbaren Bestandteil jeder Entwickler- oder Analystenwerkzeugkiste.
Benutzerdefinierte Funktionen
Eines der leistungsstärksten Merkmale von AWK ist die Möglichkeit, benutzerdefinierte Funktionen zu erstellen. Dies erlaubt uns, spezifische Berechnungen oder Transformationen zu kapseln und mehrfach wiederzuverwenden. Hier ein einfaches Beispiel:
function berechneDurchschnitt(array) {
sum = 0
for (i in array) {
sum += array[i]
}
return sum / length(array)
}
In diesem Fall definieren wir eine Funktion zur Berechnung des Durchschnitts eines Arrays. Solche Benutzermöglichkeiten steigern unsere Effizienz erheblich, da sie es uns ermöglichen, Code übersichtlicher und modularer zu gestalten.
Datenstromverarbeitung
Aber AWK kann noch mehr: Es ermöglicht auch die Verarbeitung von Datenströmen in Echtzeit. Wir können beispielsweise Eingaben aus einer Pipe lesen:
cat log.txt | awk '/Error/ {print $0}'
Hierbei filtern wir alle Zeilen aus einer Log-Datei heraus, die den Begriff „Error“ enthalten. Diese Art der Verarbeitung ist besonders nützlich für Monitoring-Tools oder bei der Analyse großer Log-Datenmengen im laufenden Betrieb.
| Funktion | Bedeutung |
|---|---|
| Benutzerdefinierte Funktionen | Kapselung spezifischer Berechnungen zur Wiederverwendbarkeit. |
| Datenstromverarbeitung | Echtzeitanalyse eingehender Datenströme durch Pipelines. |
| Mustererkennung über mehrere Dateien hinweg | Datenanalyse über verschiedene Quelldateien hinweg erleichtert das Auffinden relevanter Informationen. |
Zudem erlaubt es AWK, Muster über mehrere Dateien hinweg zu erkennen und diese Informationen zusammenzuführen. Dadurch können wir umfassendere Analysen durchführen und tiefere Einblicke gewinnen als bei einer isolierten Betrachtung einzelner Datensätze. Mit diesen erweiterten Möglichkeiten wird deutlich: Die Flexibilität und Leistungsfähigkeit von AWK macht es zu einem unverzichtbaren Werkzeug für jeden, der regelmäßig mit Textdaten arbeitet.
Vergleich mit anderen Textverarbeitungswerkzeugen auf Linux
Im Vergleich zu anderen Textverarbeitungswerkzeugen auf Linux bietet AWK einige einzigartige Vorteile, die es zu einer bevorzugten Wahl für viele Benutzer machen. Während herkömmliche Textverarbeitungsprogramme oft auf grafische Benutzeroberflächen angewiesen sind und eine steile Lernkurve haben können, ist awk linux ein leistungsfähiges Kommandozeilenwerkzeug, das durch seine Einfachheit und Flexibilität besticht. Dies ermöglicht uns, schnell komplexe Datenanalysen durchzuführen und Skripte effizient zu erstellen.
AWK vs. sed
Sowohl AWK als auch sed sind beliebte Tools zur Textbearbeitung in der Linux-Welt, doch unterscheiden sie sich grundlegend in ihrer Funktionsweise. Während sed hauptsächlich für die Bearbeitung von Textströmen konzipiert ist und einfache Ersetzungen vornimmt, bietet AWK eine umfassendere Programmierumgebung mit Funktionen wie:
- Datenanalyse basierend auf Spalten
- Mustererkennung über mehrere Zeilen hinweg
- Betriebslogik mit benutzerdefinierten Funktionen
Diese Fähigkeiten machen AWK besonders nützlich für Aufgaben, bei denen strukturierte Daten verarbeitet werden müssen. In vielen Fällen kann AWK daher als Ergänzung zu sed verwendet werden, um die Stärken beider Werkzeuge optimal auszuschöpfen.
AWK vs. grep
Ebenfalls häufig im Einsatz ist grep, ein Tool zur Suche nach Mustern innerhalb von Dateien. Obwohl grep sehr effektiv beim Filtern von Zeilen ist, kann es keine komplexen Berechnungen oder Manipulationen durchführen wie AWK. Wir können beispielsweise mit folgendem Befehl gezielt das Alter von Benutzern aus einer Liste extrahieren:
awk -F: '{print $1 ": " $3}' /etc/passwd
Hierbei nutzen wir die Trennzeichenoption (-F), um spezifische Informationen aus der Datei herauszulesen – eine Fähigkeit, die wir mit grep nicht erreichen könnten.
| Werkzeug | Anwendungsbereich |
|---|---|
| A WK | Datenanalyse und Verarbeitung strukturierter Daten. |
| s ed | Einfache Textersetzungen in Streams. |
| g rep | Mustererkennung innerhalb von Dateien ohne Manipulation. |
Letztendlich hängt die Wahl des richtigen Tools von den spezifischen Anforderungen unserer Projekte ab. Mit seinen speziellen Fähigkeiten zur Datenmanipulation hat sich jedoch gezeigt, dass AWK oft die bessere Wahl für umfangreiche Analysen und automatisierte Skriptlösungen darstellt.