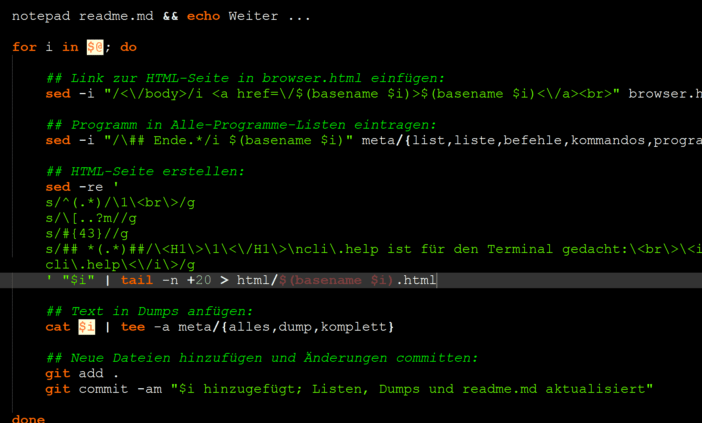
In der heutigen digitalen Welt sind effiziente Textbearbeitung und die Verwendung von Regex in der Kommandozeile unerlässlich. Mit bash sed haben wir ein mächtiges Werkzeug zur Hand, das uns hilft, Texte schnell und präzise zu bearbeiten. Egal ob wir einfache Ersetzungen vornehmen oder komplexe Muster erkennen möchten – die Möglichkeiten sind nahezu unbegrenzt.
In diesem Artikel werden wir gemeinsam die Grundlagen von bash sed erkunden und herausfinden, wie wir mit regulären Ausdrücken unsere Arbeitsabläufe optimieren können. Wir zeigen Ihnen praktische Beispiele und Tipps, die Ihnen helfen werden, Ihre Textverarbeitung erheblich zu verbessern.
Haben Sie sich jemals gefragt, wie viel Zeit Sie mit manuellen Anpassungen sparen könnten? Lassen Sie uns eintauchen in die Welt von bash sed, um diese Frage zu beantworten und Ihre Effizienz auf das nächste Level zu heben!
Bash Sed Grundlagen und Anwendungsmöglichkeiten
Bash Sed ist ein leistungsstarkes Werkzeug zur Textbearbeitung, das uns ermöglicht, Daten in Dateien und Streams effizient zu manipulieren. Es basiert auf dem Konzept der Textströme, was bedeutet, dass wir mit Zeilen arbeiten, die nacheinander verarbeitet werden. Dieses Tool finden wir häufig in der Shell-Programmierung und Automatisierung von Aufgaben. Die Anwendungsmöglichkeiten sind vielfältig und reichen von einfachen Ersetzungen bis hin zu komplexen Textanalysen.
Grundlagen von Bash Sed
Um die Funktionsweise von bash sed zu verstehen, sollten wir uns zunächst mit seinen grundlegenden Befehlen vertraut machen:
- s: Dieser Befehl steht für „substituieren“ und wird verwendet, um Texte innerhalb einer Zeile zu ersetzen.
- d: Mit diesem Befehl können wir bestimmte Zeilen aus einem Stream löschen.
- p: Dies gibt an, dass eine bestimmte Zeile ausgegeben werden soll.
Eine typische Syntax des s-Befehls sieht wie folgt aus:
sed 's/alter_text/neuer_text/' datei.txtHierbei wird „alter_text“ durch „neuer_text“ ersetzt.
Anwendungsmöglichkeiten
Die Möglichkeiten zur Anwendung von bash sed sind nahezu unbegrenzt. Hier sind einige gängige Anwendungsfälle:
- Ersetzen von Zeichenfolgen:
- Wir können spezifische Wörter oder Phrasen in einer Datei schnell ändern.
- Löschen von Linien:
- Unnötige Informationen oder leere Zeilen können entfernt werden.
- Formatierung von Ausgaben:
- Durch den Einsatz verschiedener Optionen lässt sich die Ausgabe formatieren oder strukturieren.
- Extrahieren bestimmter Teile eines Textes:
- Wir können gezielt nur relevante Informationen herausfiltern, was besonders bei großen Datenmengen nützlich ist.
Ein Beispiel für das Löschen leerer Zeilen könnte so aussehen:
sed '/^$/d' datei.txtIn diesem Fall entfernen wir alle leeren Zeilen aus „datei.txt“. Wenn wir bash sed effektiv nutzen wollen, ist es wichtig, diese Grundlagen zu beherrschen und verschiedene Kombinationen auszuprobieren.
Textbearbeitung mit Bash Sed: Einfache Beispiele
Um die praktischen Fähigkeiten von bash sed zu demonstrieren, wollen wir einige einfache, aber effektive Beispiele durchgehen. Diese Beispiele helfen uns dabei, die grundlegenden Kommandos in Aktion zu sehen und ein besseres Verständnis für die Textbearbeitung mit diesem Werkzeug zu entwickeln. Wir werden uns auf alltägliche Aufgaben konzentrieren, die oft bei der Datenbearbeitung erforderlich sind.
Ersetzen von Text
Eines der häufigsten Einsatzgebiete von bash sed ist das Ersetzen von Text innerhalb einer Datei. Nehmen wir an, wir haben eine Datei namens beispiel.txt, die den folgenden Inhalt hat:
Hallo Welt
Dies ist ein Test.
Willkommen in der Welt von Bash Sed.Wir können das Wort „Welt“ durch „Universe“ ersetzen mit folgendem Befehl:
sed 's/Welt/Universe/g' beispiel.txtDas Ergebnis würde dann so aussehen:
Hallo Universe
Dies ist ein Test.
Willkommen in der Universe von Bash Sed.Löschen unerwünschter Zeilen
Ein weiteres nützliches Beispiel ist das Löschen bestimmter Zeilen basierend auf einem Muster. Angenommen, wir möchten alle Zeilen entfernen, die das Wort „Test“ enthalten. Dazu verwenden wir den folgenden Befehl:
sed '/Test/d' beispiel.txtNach dem Ausführen dieses Befehls würden nur die Zeilen ohne das Wort „Test“ übrig bleiben.
Ausgabe bestimmter Linien
Bash sed ermöglicht es uns auch, gezielt bestimmte Linien auszugeben. Wenn wir beispielsweise nur die erste Zeile aus unserer Datei anzeigen möchten, können wir dies mit dem folgenden Befehl tun:
sed -n '1p' beispiel.txtDadurch erhalten wir als Ausgabe lediglich:
Hallo WeltKombinierte Operationen
Zudem können mehrere Operationen miteinander kombiniert werden. Zum Beispiel könnten wir sowohl „Welt“ durch „Universum“ ersetzen als auch gleichzeitig alle Zeilen löschen, die das Wort „Test“ enthalten:
sed -e 's/Welt/Universum/g' -e '/Test/d' beispiel.txtThis command is powerful as it allows us to perform multiple modifications with a single execution of bash sed.
Mithilfe dieser einfachen Beispiele haben wir gesehen, wie vielseitig bash sed sein kann und wie effizient es zur Textbearbeitung eingesetzt werden kann. Indem wir diese grundlegenden Kommandos verstehen und anwenden, legen wir den Grundstein für komplexere Anwendungen und Automatisierungen in Zukunft.
Regex in Bash Sed: Mustererkennung und Ersetzung
In dieser Sektion widmen wir uns der mächtigen Welt der regulären Ausdrücke (Regex) in bash sed. Regex ermöglicht es uns, komplexe Muster zu erkennen und präzise Ersetzungen in Texten vorzunehmen. Diese Fähigkeit ist besonders nützlich, wenn wir mit unstrukturierten Daten arbeiten oder spezifische Änderungen in großen Dateien durchführen möchten. Wir werden einige grundlegende Konzepte und Beispiele durchgehen, um die Anwendung von Regex in Verbindung mit bash sed besser zu verstehen.
Mustererkennung mit Regex
Ein zentraler Aspekt von regex ist die Fähigkeit, unterschiedliche Muster innerhalb eines Textes zu identifizieren. Um dies zu veranschaulichen, nehmen wir an, dass wir alle Zeilen aus einer Datei extrahieren möchten, die eine E-Mail-Adresse enthalten. Dazu verwenden wir den folgenden Befehl:
sed -n '/[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}/p' beispiel.txtDieser Befehl sucht nach dem Muster einer typischen E-Mail-Adresse und gibt nur die entsprechenden Zeilen aus.
Ersatz mit regulären Ausdrücken
Neben der Mustersuche können wir auch gezielte Ersetzungen vornehmen. Wenn wir beispielsweise das Wort „Test“ in unserer Datei durch „Überprüfung“ ersetzen wollen und dabei sicherstellen möchten, dass nur vollständige Übereinstimmungen berücksichtigt werden (also nicht Teil eines anderen Wortes), können wir folgendes einsetzen:
sed 's/bTestb/Überprüfung/g' beispiel.txtHierbei stellt der Ausdruck b sicher, dass „Test“ nur ersetzt wird, wenn es als ganzes Wort auftritt.
Kombinierte Verwendung von Mustern
Eine weitere interessante Möglichkeit besteht darin, mehrere regex-Muster gleichzeitig anzuwenden. Zum Beispiel könnten wir alle Zeilen löschen, die entweder das Wort „Fehler“ oder eine bestimmte E-Mail-Domain enthalten:
sed '/bFehlerb/d; /@beispiel.com/d' beispiel.txtDadurch sind unsere Befehle sehr flexibel und ermöglichen vielfältige Anpassungen an unseren Textdaten.
| Befehl | Bedeutung |
|---|---|
| /[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}/ | Sucht nach E-Mail-Adressen im Text. |
| bTestb | Ersatz nur für das gesamte Wort „Test“. |
| /@beispiel.com/d | Löscht Zeilen mit der Domain „@beispiel.com“. |
Anhand dieser Beispiele haben wir gesehen, wie leistungsstark regex innerhalb von bash sed sein kann. Durch die Kombination von Mustern zur Erkennung und gezielten Ersetzung stellen wir sicher, dass unsere Textbearbeitung sowohl effektiv als auch effizient erfolgt. In den nächsten Abschnitten werden wir Tipps zur Optimierung unserer Kommandos sowie häufige Fehler behandeln und deren Lösungen erörtern.
Tipps zur Optimierung von Bash Sed Kommandos
Um die Effizienz und Effektivität unserer bash sed Kommandos zu maximieren, sollten wir einige bewährte Tipps berücksichtigen. Diese Optimierungen können nicht nur die Ausführungsgeschwindigkeit erhöhen, sondern auch den Code lesbarer und wartungsfreundlicher machen. Im Folgenden präsentieren wir einige Strategien, die uns helfen werden, unsere bash sed Kommandos auf das nächste Level zu heben.
1. Vermeidung unnötiger Prozesse
Ein häufiger Fehler ist die Verwendung von mehreren Sed-Befehlen in einer Pipeline. Stattdessen können wir oft alle gewünschten Änderungen in einem einzigen Sed-Befehl kombinieren. Dies reduziert die Anzahl der Prozesse und erhöht die Geschwindigkeit erheblich. Zum Beispiel anstatt:
cat beispiel.txt | sed 's/alt/neuer/g' | sed '/uninteressant/d'könnten wir schreiben:
sed -e 's/alt/neuer/g' -e '/uninteressant/d' beispiel.txt2. Nutzung von Variablen für wiederholte Muster
Wenn wir ein bestimmtes Muster mehrmals verwenden müssen, kann es hilfreich sein, dieses Muster in eine Variable zu speichern. Dies macht den Code nicht nur kürzer, sondern verbessert auch die Lesbarkeit:
muster='[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}'
sed -n "/$muster/p" beispiel.txt3. Anpassen des Puffergrößenparameters
Die Leistung von bash sed kann durch das Anpassen der Puffergröße optimiert werden. Durch Erhöhen oder Verringern der Standardpuffergröße mit dem -b Flag können wir je nach Dateigröße eine bessere Performance erzielen.
4. Verwendung von Scripts statt Inline-Kommandos
Für komplexere Aufgaben kann es vorteilhaft sein, Sed-Skripte zu erstellen und diese auszuführen anstatt lange Inline-Kommandos zu verwenden. Dies führt nicht nur zu einer besseren Strukturierung unseres Codes, sondern erleichtert auch zukünftige Anpassungen.
# script.sed
s/alt/neuer/g
/uninteressant/d
# Ausführen des Skripts
sed -f script.sed beispiel.txt| Tipps | Bedeutung |
|---|---|
| Kombination von Befehlen | Reduziert Prozessanzahl und steigert Geschwindigkeit. |
| Nutzung von Variablen | Verbessert Lesbarkeit bei wiederholten Mustern. |
| Anpassung der Puffergröße | Optimiert Leistung basierend auf Dateigröße. |
Durch diese Ansätze sind wir in der Lage, bash sed effizienter einzusetzen und gleichzeitig unseren Arbeitsablauf zu verbessern. Mit diesen Optimierungen schaffen wir nicht nur schnellere Kommandos sondern auch einen klareren Überblick über unsere Textbearbeitungsprojekte in der Kommandozeile. In den nächsten Abschnitten werden wir häufige Fehler bei der Verwendung von Sed sowie deren Lösungen betrachten, um sicherzustellen, dass unsere Arbeit reibungslos verläuft.
Häufige Fehler bei der Verwendung von Sed und deren Lösungen
Bei der Arbeit mit bash sed können wir auf verschiedene häufige Fehler stoßen, die unsere Textbearbeitung erheblich beeinträchtigen können. Um diese Fallstricke zu vermeiden und effizienter zu arbeiten, ist es hilfreich, sich der typischen Probleme bewusst zu sein und deren Lösungen anzuwenden. Im Folgenden werden einige dieser Fehler und die entsprechenden Lösungsansätze vorgestellt.
1. Falsche Verwendung von Escape-Zeichen
Ein gängiger Fehler besteht darin, Escape-Zeichen nicht korrekt zu nutzen. Wenn wir beispielsweise ein spezielles Zeichen wie das Slash (/) oder das Dollarzeichen ($) in unserem Muster verwenden, müssen wir sicherstellen, dass sie richtig escaped sind. Andernfalls interpretiert sed sie möglicherweise falsch.
Lösung
Stellen Sie sicher, dass Sie Escape-Zeichen verwenden, wenn nötig:
sed 's//path/to/file//new/path/g' beispiel.txt2. Unzureichende Tests vor der Anwendung
Ein weiterer häufiger Fehler ist die direkte Anwendung von Sed-Befehlen auf Produktionsdateien ohne vorherige Tests an einer Kopie der Datei oder im Trockentestmodus (-n). Dies kann dazu führen, dass unbeabsichtigte Änderungen vorgenommen werden.
Lösung
Testen Sie Ihre Befehle zuerst mit -n, um nur die Ausgabe anzuzeigen:
sed -n 's/muster/neuer_text/p' beispiel.txt3. Missverständnisse bei den Modifikatoren
Manchmal verwenden wir Modifikatoren wie g (global) oder p (print) nicht korrekt und erzielen daher nicht das gewünschte Ergebnis. Das Fehlen des Modifiers kann dazu führen, dass nur das erste Vorkommen eines Musters ersetzt wird.
Lösung
Achten Sie darauf, den richtigen Modifikator für Ihre Anforderungen hinzuzufügen:
sed 's/muster/neuer_text/g' beispiel.txt| Fehler | Bedeutung |
|---|---|
| Falsche Verwendung von Escape-Zeichen | Verhindert korrekte Mustererkennung |
| Unzureichende Tests | Führt zu unerwünschten Änderungen |
| Missverständnisse bei Modifikatoren | Ersetzt nicht alle Vorkommen eines Musters |
Durch das Bewusstsein über diese häufigen Fehler und ihre Lösungen können wir unsere Nutzung von bash sed optimieren und eine effektivere Textbearbeitung in der Kommandozeile erreichen.