Datenbanken sind das Rückgrat moderner Informationssysteme. Ein gutes Datenbank Beispiel zeigt uns nicht nur, wie wir Informationen strukturieren können, sondern auch, wie wir sie effizient nutzen. In diesem Artikel werden wir den Aufbau und die Nutzung von Datenbanken detailliert erläutern und dabei praktische Beispiele verwenden, um unser Verständnis zu vertiefen.
Wir alle wissen, dass eine solide Datenbank-Architektur entscheidend für den Erfolg eines Unternehmens ist. Doch wie setzen wir diese Architektur in der Praxis um? Wir werden verschiedene Typen von Datenbanken betrachten und deren spezifische Anwendungsfälle untersuchen. Dabei helfen uns anschauliche Beispiele zu verstehen, welche Vorteile eine gut gestaltete Datenbank mit sich bringt.
Sind Sie bereit zu entdecken, wie Sie Ihre eigene Datenbank effektiv aufbauen und nutzen können? Lassen Sie uns gemeinsam in die faszinierende Welt der Datenbanken eintauchen!
Datenbank Beispiel: Grundlegende Struktur und Komponenten
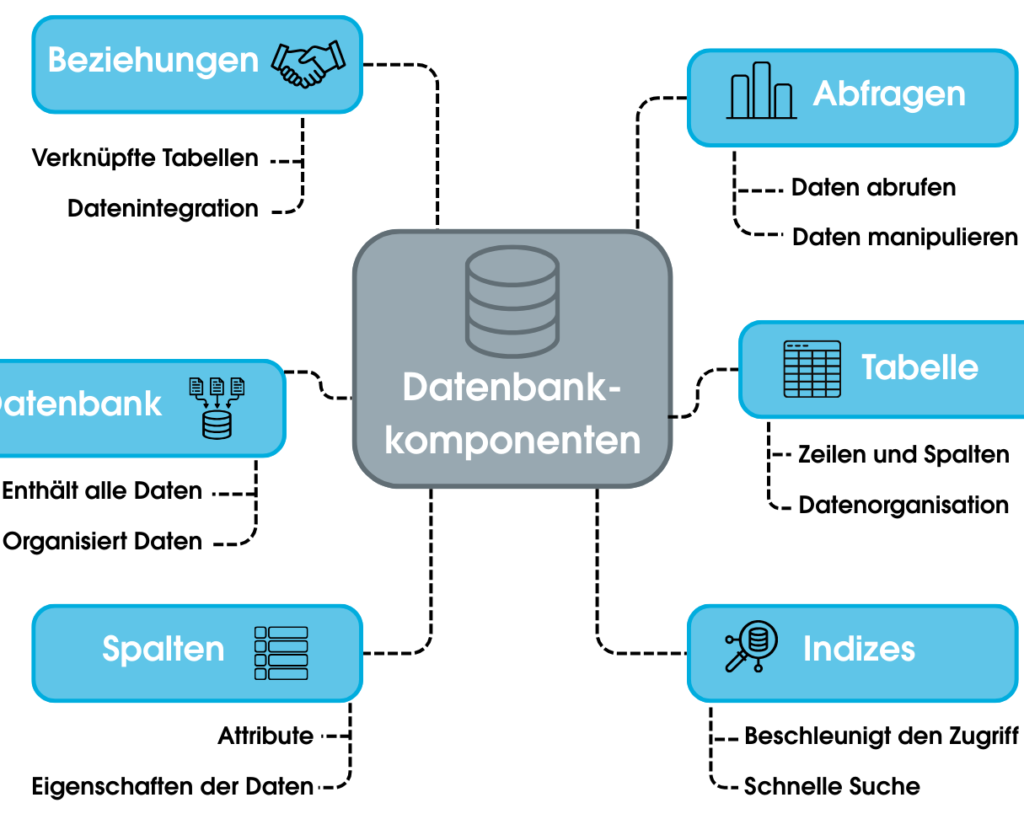
Die grundlegende Struktur einer Datenbank ist entscheidend für ihre Effizienz und Benutzerfreundlichkeit. In diesem Abschnitt werden wir die wesentlichen Komponenten betrachten, die jede Datenbank definieren. Zu diesen Komponenten gehören Tabellen, Datensätze und Felder, die gemeinsam ein System bilden, das es ermöglicht, Informationen strukturiert zu speichern und abzurufen.
Eine typische Datenbank besteht aus folgenden Hauptkomponenten:
- Tabellen: Diese sind die grundlegendsten Strukturen in einer Datenbank. Jede Tabelle speichert Daten zu einem bestimmten Thema.
- Felder: Jedes Feld innerhalb einer Tabelle entspricht einem Attribut der gespeicherten Informationen. Zum Beispiel könnte eine Tabelle über Kunden Felder wie Name, Adresse und Telefonnummer enthalten.
- Datensätze: Ein Datensatz repräsentiert eine vollständige Sammlung von Informationen innerhalb einer Tabelle. Jeder Datensatz enthält Werte für alle Felder der Tabelle.
Beziehungen zwischen Tabellen
Ein wichtiges Merkmal von relationalen Datenbanken ist die Möglichkeit, Beziehungen zwischen verschiedenen Tabellen herzustellen. Dies erhöht die Flexibilität und den Zugriff auf verknüpfte Informationen. Die häufigsten Beziehungstypen sind:
- Eins-zu-eins-Beziehung: Jeder Datensatz in der ersten Tabelle entspricht genau einem Datensatz in der zweiten Tabelle.
- Eins-zu-viele-Beziehung: Ein Datensatz in der ersten Tabelle kann mit mehreren Datensätzen in der zweiten Tabelle verknüpft sein.
- Viele-zu-viele-Beziehung: Mehrere Datensätze in der ersten Tabelle können mit mehreren Datensätzen in der zweiten Tabelle verbunden sein.
Diese Beziehungen ermöglichen es uns, komplexe Abfragen durchzuführen und relevante Informationen effizient abzurufen.
Indizes zur Optimierung
Ein weiterer wichtiger Aspekt bei der Gestaltung unserer Datenbankbeispiele sind Indizes. Sie verbessern die Geschwindigkeit von Abfragen erheblich, indem sie den Zugriff auf bestimmte Felder oder Kombinationen von Feldern optimieren. Wir sollten jedoch darauf achten, dass das Anlegen zu vieler Indizes auch nachteilige Auswirkungen auf die Leistung haben kann – insbesondere bei Schreiboperationen.
Um dies zu verdeutlichen hier eine einfache Darstellung:
| Komponente | Funktion |
|---|---|
| Tabellen | Speicherung strukturierter Daten |
| Felder | Attribute zur Beschreibung von Daten |
| Datensätze | Kombination aller Attribute eines Objekts |
| Indizes | Schnellerer Zugriff auf häufig abgefragte Datenfelder |
Durch das Verständnis dieser grundlegenden Struktur und Komponenten legen wir den Grundstein für effektive Nutzung unserer Beispiele im Bereich Datenbanken sowie deren Anwendungsmöglichkeiten im praktischen Alltag.
Arten von Datenbanken und deren Anwendungen
In der heutigen digitalen Welt gibt es eine Vielzahl von Datenbanken, die jeweils für unterschiedliche Anwendungen und Bedürfnisse entwickelt wurden. Die Wahl der richtigen Datenbank hängt oft von den spezifischen Anforderungen an Flexibilität, Skalierbarkeit und Datentypen ab. Im Folgenden stellen wir einige der gängigsten Arten von Datenbanken sowie deren Anwendungsbereiche vor.
- Relationale Datenbanken: Diese Art von Datenbank verwendet Tabellen zur Speicherung von Informationen, die durch Beziehungen miteinander verknüpft sind. Sie eignen sich hervorragend für strukturierte Daten und sind ideal für Anwendungen wie Kundenmanagement oder Buchhaltung.
- NoSQL-Datenbanken: NoSQL-Datenbanken bieten flexible Datenspeicherungsmodelle, die nicht auf Tabellen beschränkt sind. Sie eignen sich besonders gut für große Mengen unstrukturierter Daten wie in sozialen Netzwerken oder bei Echtzeitanalysen.
- Objektorientierte Datenbanken: Diese speichern Informationen in Form von Objekten, ähnlich wie in objektorientierten Programmiersprachen. Sie finden Anwendung in komplexen Systemen, etwa bei CAD-Anwendungen oder Multimedia-Software.
- Hierarchische Datenbanken: In hierarchischen Datenbanken werden Informationen in einer baumartigen Struktur organisiert. Diese Art wird häufig in Mainframe-Systemen verwendet, wo es wichtig ist, eine klare Hierarchie darzustellen.
- Netzwerkdatenbanken: Ähnlich wie hierarchische Systeme ermöglichen Netzwerkdatenbanken komplexere Beziehungen durch ein netzwerkbasiertes Modell. Dies eignet sich gut für Anwendungen mit vielen zugehörigen Datensätzen.
Anwendungsszenarien
Jede dieser Arten hat ihre eigenen Stärken und Schwächen sowie spezifische Anwendungsszenarien:
| Datenbanktyp | Anwendungsbeispiele | ||
|---|---|---|---|
| Relationale Datenbank | Kundenverwaltungssysteme, Buchhaltungssoftware | ||
| NoSQL-Datenbank | Echtzeitanalyse großer Datensätze, soziale Netzwerke | ||
| Objektorientierte Datenbank | CAD-Anwendungen, Multimedia-Projekte | ||
| Hierarchische Datenbank | Mainframe-Systeme zur Verwaltung klarer Hierarchien | ||
| Netzwerkdatenbank | Anwendungen mit vielen verknüpften Datensätzen |
Bedenken wir auch die wachsende Bedeutung des Cloud-Computing: Viele moderne Anwendungen nutzen cloudbasierte Lösungen zur Bereitstellung flexibler und skalierbarer Speicheroptionen über verschiedene Typen hinweg. So können Unternehmen agil auf Veränderungen reagieren und ihre Ressourcen effizient verwalten.
Mithilfe dieses Verständnisses über die verschiedenen Arten von Datenbanken und deren jeweilige Einsatzmöglichkeiten können wir gezielt entscheiden, welche Lösung am besten zu unseren spezifischen Anforderungen passt – sei es bei der Entwicklung eines neuen Projekts oder der Optimierung bestehender Systeme.
Wie man ein effektives Datenbankbeispiel erstellt
Um ein effektives Datenbankbeispiel zu erstellen, müssen wir einige wichtige Schritte und Überlegungen berücksichtigen. Der erste Schritt besteht darin, die Datenanforderungen klar zu definieren. Dazu gehört das Verständnis, welche Informationen gespeichert werden sollen und wie diese miteinander in Beziehung stehen. Ein gut durchdachtes Konzept hilft uns nicht nur bei der Strukturierung der Daten, sondern auch bei der späteren Nutzung.
Ein weiterer zentraler Aspekt ist die Wahl des richtigen Datenbanktyps. Je nach Anwendungsfall können relationale oder NoSQL-Datenbanken geeigneter sein. Bei einem relationalen Ansatz sollten Tabellen mit klar definierten Beziehungen erstellt werden, während NoSQL-Modelle mehr Flexibilität bieten und sich besser für unstrukturierte Daten eignen.
Schritte zur Erstellung eines effektiven Datenbankbeispiels
- Bedarfsanalyse durchführen: Wir müssen klären, welche spezifischen Anforderungen an die Datenbank bestehen.
- Datenmodell entwerfen: Dabei erstellen wir ein logisches Modell, das alle relevanten Entitäten und deren Beziehungen umfasst.
- Tabellenstruktur festlegen: Für relationale Systeme bedeutet dies die Definition von Primär- und Fremdschlüsseln sowie von Attributen jeder Tabelle.
- Dateneingabemethoden bestimmen: Wir entscheiden darüber, wie Daten in die Datenbank eingegeben werden – manuell oder automatisiert.
- Sicherheitsaspekte beachten: Die Implementierung von Sicherheitsmaßnahmen zum Schutz sensibler Daten ist unerlässlich.
Beispiel für eine einfache relationale Datenbank
Um unser Vorgehen zu veranschaulichen, betrachten wir ein einfaches Beispiel für eine Kundenverwaltung:
| Kunden-ID | Name | |
|---|---|---|
| 1 | Max Mustermann | max@beispiel.com |
| 2 | Erika Musterfrau | erika@beispiel.com |
In diesem Beispiel haben wir eine ganz einfache Tabelle mit Kundendaten erstellt. Hierbei sind die Kunden-ID als Primärschlüssel definiert, um jeden Datensatz eindeutig zu identifizieren.
Durch sorgfältige Planung und Ausführung dieser Schritte stellen wir sicher, dass unser datenbank beispiel sowohl funktional als auch effizient ist und den Anforderungen unserer Anwendung gerecht wird.
Wichtige Abfragen zur Nutzung von Datenbanken
Um die volle Leistung unserer Datenbank zu nutzen, ist es entscheidend, geeignete Abfragen zu formulieren. Diese Abfragen ermöglichen es uns, gezielt auf die benötigten Informationen zuzugreifen und Daten effizient auszuwerten. Dabei sollten wir uns bewusst sein, dass eine präzise Gestaltung der Abfragen nicht nur die Antwortzeiten verkürzt, sondern auch die Belastung des Systems reduziert.
Grundlegende Abfragearten
Bei der Nutzung von Datenbanken stoßen wir auf verschiedene Arten von Abfragen, die jeweils spezifische Zwecke erfüllen:
- Select-Abfragen: Diese werden verwendet, um bestimmte Datensätze aus einer Tabelle abzurufen.
- Join-Abfragen: Hierbei handelt es sich um einen Mechanismus zur Verknüpfung von Daten aus mehreren Tabellen basierend auf gemeinsamen Schlüsseln.
- Aggregatabfragen: Sie fassen mehrere Werte zusammen und liefern Ergebnisse wie Summe oder Durchschnitt für definierte Gruppen.
- Update- und Delete-Abfragen: Mit diesen können bestehende Datensätze aktualisiert oder gelöscht werden.
Bedeutung der richtigen Syntax
Die korrekte Anwendung der Syntax spielt eine zentrale Rolle bei der Formulierung effektiver Datenbankabfragen. Fehler in den Anweisungen können dazu führen, dass falsche oder keine Ergebnisse zurückgegeben werden. Daher empfehlen wir folgendes Vorgehen:
- Sorgfältige Überprüfung der SQL-Syntax vor dem Ausführen einer Abfrage.
- Nutzung von Kommentaren innerhalb komplexer Anweisungen zur besseren Nachvollziehbarkeit.
- Einsatz von Entwicklungsumgebungen mit Syntax-Hervorhebung zur Minimierung von Fehlern.
Optimierung Ihrer Abfragen
Eine gut optimierte Abfrage kann den Unterschied zwischen akzeptabler und hervorragender Leistung ausmachen. Hier sind einige Tipps zur Verbesserung unserer Abfragetechniken:
- Anwendung von Indizes: Sie beschleunigen den Zugriff auf häufig abgerufene Spalten erheblich.
- Einschränkung des Ergebnismenge: Durch gezielte Filterung vermeiden wir unnötige Datenübertragungen und verbessern die Ladezeiten.
- Nutzung von Caching: Häufige Anfragen sollten zwischengespeichert werden, um wiederholte Zugriffe schneller zu gestalten.
Durch das Verständnis dieser grundlegenden Aspekte zur Formulierung und Optimierung von Datenbankabfragen stellen wir sicher, dass unser datenbank beispiel nicht nur effektiv funktioniert, sondern auch optimal an unsere Anforderungen angepasst ist. Dies ermöglicht uns eine effiziente Handhabung großer Datenmengen und verbessert insgesamt unsere Arbeitsabläufe im Umgang mit Informationen.
Tipps zur Optimierung der Datenbanknutzung
Die Optimierung der Datenbanknutzung ist für die Effizienz unserer Anwendungen von großer Bedeutung. Durch gezielte Maßnahmen können wir nicht nur die Geschwindigkeit erhöhen, sondern auch die Ressourcen schonen und die Benutzererfahrung verbessern. In diesem Abschnitt teilen wir einige bewährte Tipps, um unsere datenbank beispiel optimal zu nutzen.
Einsatz von Indizes
Indizes sind entscheidend für eine schnellere Datenabfrage. Sie ermöglichen den schnellen Zugriff auf bestimmte Spalten einer Tabelle ohne das Durchsuchen aller Datensätze. Wir sollten jedoch sorgfältig auswählen, welche Spalten indiziert werden sollen, da zu viele Indizes auch die Leistung beim Einfügen oder Aktualisieren von Daten beeinträchtigen können.
Datenreduzierung durch Filterung
Eine weitere Möglichkeit zur Optimierung besteht darin, bei Abfragen gezielt Filter anzuwenden. Durch präzise Bedingungen in unseren SQL-Abfragen reduzieren wir die Menge der zurückgegebenen Daten erheblich und verbessern so sowohl Ladezeiten als auch Systemressourcen:
- Verwendung von WHERE-Klauseln zur Einschränkung der Ergebnismenge.
- Nutzung von LIMIT-Anweisungen, um nur eine Teilmenge der Ergebnisse abzurufen.
- Aggregieren von Daten mit GROUP BY zur Reduzierung des Volumens an überflüssigen Informationen.
Caching-Strategien implementieren
Caching kann signifikant zur Verbesserung der Performance beitragen. Indem wir häufige Abfragen im Cache speichern, vermeiden wir wiederholte Zugriffe auf die Datenbank und reduzieren somit Latenzzeiten:
- Implementierung eines Caches für statische oder wenig veränderte Daten.
- Nutzung von Technologien wie Redis oder Memcached für effiziente Cache-Lösungen.
- Anpassung des Caching-Zeitplans basierend auf dem Änderungsbedarf unserer Daten.
Durch diese Strategien zur Optimierung unserer datenbank beispiel stellen wir sicher, dass unsere Systeme effizient arbeiten und gleichzeitig einer hohen Benutzerlast standhalten können. Dabei ist es wichtig, regelmäßig Leistungsanalysen durchzuführen und Anpassungen vorzunehmen, um den sich ändernden Anforderungen gerecht zu werden.