In der heutigen datengetriebenen Welt ist lineare Regression ein unverzichtbares Werkzeug für Analysten und Wissenschaftler. Wir alle möchten Muster in unseren Daten erkennen und Vorhersagen treffen, und genau hier kommt die lineare Regression ins Spiel. In diesem Artikel werden wir ein spannendes lineares Regression Beispiel untersuchen, das uns hilft, die Theorie in die Praxis umzusetzen.
Durch anschauliche Erklärungen und praktische Anwendungen zeigen wir, wie diese Methode funktioniert und wo sie eingesetzt wird. Wir werden auch auf verschiedene Szenarien eingehen in denen lineare Regression effektiv genutzt werden kann um wertvolle Erkenntnisse zu gewinnen. Haben Sie sich schon einmal gefragt wie Unternehmen ihre Verkaufszahlen vorhersagen oder Trends analysieren? Mit unserer Analyse der linearen Regression können Sie diese Fragen beantworten!
Anwendung der linearen Regression in der Praxis
Die Anwendung der linearen Regression in der Praxis ist weit verbreitet und spielt eine entscheidende Rolle in verschiedenen Bereichen wie Wirtschaft, Sozialwissenschaften, Gesundheitswesen und Ingenieurwesen. Durch die Verwendung von linearer Regression können wir Muster in Daten erkennen, Vorhersagen treffen und fundierte Entscheidungen basierend auf quantitativen Analysen treffen. Um den praktischen Nutzen besser zu verstehen, betrachten wir einige spezifische Anwendungsfälle.
Anwendungsbeispiele
- Wirtschaftliche Analysen: Unternehmen nutzen lineare Regression zur Analyse von Verkaufszahlen in Abhängigkeit von Werbeausgaben oder saisonalen Trends. So kann ermittelt werden, wie sich Änderungen im Marketingbudget auf den Umsatz auswirken.
- Medizinische Forschung: In der Gesundheitsforschung wird die lineare Regression häufig verwendet, um Zusammenhänge zwischen verschiedenen Variablen zu untersuchen, beispielsweise zwischen dem Body-Mass-Index (BMI) und dem Risiko für bestimmte Krankheiten.
- Sozialwissenschaften: Forscher verwenden diese Methode zur Analyse des Einflusses von Bildung auf das Einkommen oder andere soziale Faktoren. Hierbei können verschiedene Faktoren als unabhängige Variablen betrachtet werden, um deren Auswirkungen zu isolieren.
- Ingenieurwesen: In technischen Anwendungen hilft die lineare Regression bei der Vorhersage von Materialverhalten oder bei der Qualitätskontrolle durch statistische Prozesskontrolle.
Vorteile der Anwendung
Die Nutzung der linearen Regression bringt mehrere Vorteile mit sich:
- Sie ist einfach zu implementieren und zu interpretieren.
- Die Ergebnisse sind leicht verständlich aufgrund ihrer mathematischen Basis.
- Sie ermöglicht es uns, präzise Vorhersagen für zukünftige Ereignisse zu treffen.
- Die Methode kann auch als Grundlage für komplexere Modelle dienen.
Insgesamt zeigt sich, dass die Anwendung der linearen Regression in vielen verschiedenen Disziplinen nicht nur hilfreich ist, sondern oft unerlässlich für tiefere Einblicke in Datenanalysen und Entscheidungsprozesse darstellt.
Erläuterung des Modells der linearen Regression
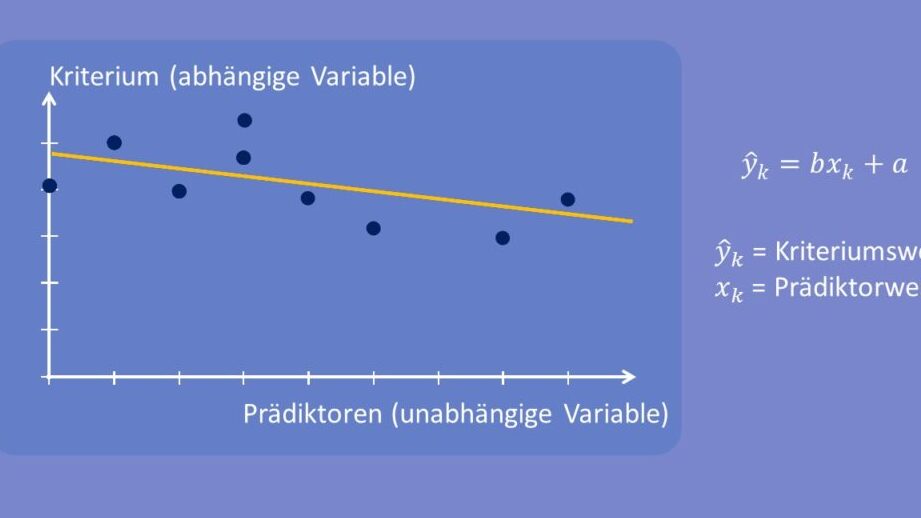
Das Modell der linearen Regression ist ein fundamentales Werkzeug in der Statistik und Datenanalyse, das uns ermöglicht, den Zusammenhang zwischen einer abhängigen Variablen und einer oder mehreren unabhängigen Variablen zu untersuchen. Bei der linearen Regression gehen wir davon aus, dass dieser Zusammenhang linear ist, was bedeutet, dass Änderungen in den unabhängigen Variablen proportional zu Veränderungen in der abhängigen Variable führen. Mathematisch wird dies durch die Gleichung (Y = a + bX) dargestellt, wobei (Y) die abhängige Variable, (X) die unabhängige Variable, (a) der Achsenabschnitt und (b) die Steigung ist.
Um das Modell besser zu verstehen, betrachten wir einige zentrale Konzepte:
1. Die Annahmen des Modells
Die korrekte Anwendung des Modells beruht auf mehreren grundlegenden Annahmen:
- Linearität: Der Zusammenhang zwischen den Variablen muss linear sein.
- Homoskedastizität: Die Varianz der Fehler sollte konstant sein über alle Werte von X.
- Unabhängigkeit: Die Beobachtungen müssen unabhängig voneinander sein.
- Normalverteilung der Fehler: Die Residuen (Fehlerterme) sollten normalverteilt sein.
Diese Annahmen müssen überprüft werden, um die Gültigkeit des Modells sicherzustellen.
2. Interpretation der Koeffizienten
Die Koeffizienten des Modells sind entscheidend für unsere Interpretationen:
- Der Achsenabschnitt ((a)) gibt an, welchen Wert die abhängige Variable annimmt, wenn alle unabhängigen Variablen gleich null sind.
- Die Steigung ((b)) zeigt an, wie sich die abhängige Variable verändert, wenn sich die unabhängige Variable um eine Einheit erhöht. Eine positive Steigung deutet auf einen positiven Zusammenhang hin; eine negative Steigung zeigt hingegen einen negativen Zusammenhang an.
3. Güte des Modells
Zur Bewertung eines Regressionsmodells verwenden wir verschiedene Statistiken:
- R² (Bestimmtheitsmaß): Es misst den Anteil der Variation in der abhängigen Variable, welcher durch das Modell erklärt wird. Ein R²-Wert nahe 1 deutet darauf hin, dass das Modell gut passt.
| Maßnahme | Bedeutung |
|---|---|
| R² | Anteil erklärter Varianz |
| p-Wert | Signifikanztest für Koeffizienten |
| F-Test | Gesamtmodelltest |
Ein signifikanter p-Wert (<0.05) zeigt an, dass es einen statistisch signifikanten Einfluss einer oder mehrerer unabhängiger Variablen auf die abhängige Variable gibt.
Mit diesen Konzepten im Hinterkopf können wir nun mit konkreten Beispielen zur Anwendung sowie zur Durchführung von Datenanalysen mit linearer Regression fortfahren.
Beispielhafte Datenanalyse mit linearer Regression
Um die Konzepte der linearen Regression praktisch zu veranschaulichen, betrachten wir ein Beispiel aus der realen Welt. Nehmen wir an, wir möchten den Einfluss der Anzahl der Lernstunden auf die Prüfungsergebnisse von Schülern analysieren. In diesem Kontext ist die abhängige Variable das Prüfungsergebnis (Y), während die unabhängige Variable die Anzahl der Lernstunden (X) darstellt.
Wir haben folgende fiktive Daten gesammelt:
| Lernstunden (X) | Prüfungsergebnis (Y) |
|---|---|
| 1 | 50 |
| 2 | 55 |
| 3 | 65 |
| 4 | 70 |
| 5 | 80 |
Anhand dieser Daten können wir nun eine lineare Regression durchführen, um herauszufinden, ob es einen signifikanten Zusammenhang zwischen den Lernstunden und den Prüfungsergebnissen gibt.
Durchführung der Analyse
- Datenvisualisierung: Zunächst visualisieren wir unsere Daten in einem Streudiagramm, um einen ersten Eindruck vom möglichen Zusammenhang zu bekommen. Wir erwarten eine positive Korrelation zwischen den Lernstunden und den Ergebnissen.
- Modellanpassung: Mit statistischen Softwaretools oder Programmiersprachen wie Python oder R können wir das Regressionsmodell anpassen. Die resultierende Gleichung könnte beispielsweise folgendermaßen aussehen:
[
Y = a + bX
]
Nach Berechnung erhalten wir möglicherweise (a = 45) und (b = 7). Dies führt zur Gleichung:
[
Y = 45 + 7X
]
- Interpretation der Ergebnisse: In diesem Modell zeigt (a), dass ein Schüler ohne Lernen ein Ergebnis von etwa 45 Punkten erwarten kann. Der Koeffizient (b) deutet darauf hin, dass jede zusätzliche Stunde Lernen mit einer Erhöhung des Ergebnisses um 7 Punkte verbunden ist.
Bewertung des Modells
Um die Güte unseres Modells zu bewerten, berechnen wir das Bestimmtheitsmaß (R²). Angenommen, unser Modell hat ein (R²)-Wert von 0,92, was bedeutet, dass unser Modell 92% der Varianz in den Prüfungsergebnissen erklärt. Dies zeigt uns eine hohe Anpassungsqualität.
Zusätzlich führen wir einen Signifikanztest für unseren Koeffizienten durch (p-Wert). Ein p-Wert unter 0,05 würde darauf hindeuten, dass unsere unabhängigen Variablen statistisch signifikant sind und somit glaubwürdig zur Vorhersage des Prüfungsergebnisses beitragen.
Durch diese können wir nicht nur Muster erkennen, sondern auch praktische Entscheidungen treffen basierend auf quantitativen Analysen – was eine zentrale Stärke dieses Verfahrens darstellt.
Vorteile und Nachteile der linearen Regression
Die lineare Regression hat sowohl Vorteile als auch Nachteile, die wir im Kontext unserer Analyse der Lernstunden und Prüfungsergebnisse berücksichtigen sollten. Durch das Verständnis dieser Aspekte können wir besser einschätzen, wann und wie dieses Modell am besten eingesetzt wird.
Vorteile der linearen Regression
- Einfachheit: Die lineare Regression ist einfach zu verstehen und zu interpretieren. Die mathematische Formulierung ist klar, was es uns ermöglicht, schnell Einsichten aus den Ergebnissen zu gewinnen.
- Effizienz: Bei großen Datensätzen benötigt die lineare Regression relativ wenig Rechenleistung im Vergleich zu komplexeren Modellen. Dies macht sie besonders nützlich für schnelle Analysen.
- Transparenz: Die Ergebnisse sind leicht nachvollziehbar, da jede unabhängige Variable ihren eigenen Einfluss auf die abhängige Variable zeigt, was durch die Koeffizienten in unserem Modell dargestellt wird.
- Vielseitigkeit: Sie kann in verschiedenen Bereichen angewendet werden, von der Wirtschaft über die Medizin bis hin zur Sozialwissenschaft.
Nachteile der linearen Regression
- Annahmen über Linearität: Ein wesentlicher Nachteil ist die Annahme einer linearen Beziehung zwischen den Variablen. In vielen realen Szenarien könnte diese Annahme nicht zutreffen, wodurch das Modell ungenau wird.
- Empfindlichkeit gegenüber Ausreißern: Lineare Modelle sind anfällig für Ausreißer in den Daten, welche das Ergebnis erheblich beeinflussen können und somit falsche Schlussfolgerungen hervorrufen könnten.
- Multikollinearität: Wenn mehrere unabhängige Variablen stark korreliert sind, kann dies zu Problemen bei der Schätzung der Koeffizienten führen und unsere Interpretationen verwässern.
- Begrenzte Fähigkeit zur Modellierung komplexer Beziehungen: Während wir möglicherweise einen positiven Trend zwischen Lernstunden und Prüfungsergebnissen beobachten können, erfasst die lineare Regression keine nichtlinearen Zusammenhänge oder Wechselwirkungen zwischen Variablen effektiv.
Insgesamt bietet uns die lineare regression beispiel eine solide Grundlage für viele analytische Aufgabenstellungen; dennoch müssen wir ihre Limitationen stets im Hinterkopf behalten und gegebenenfalls alternative Modelle in Betracht ziehen.
Häufige Fehler bei der Anwendung von Regressionsmodellen
Die Anwendung von Regressionsmodellen, insbesondere der linearen Regression, kann häufig durch verschiedene Fehler beeinträchtigt werden. Diese Fehler können nicht nur die Ergebnisse verzerren, sondern auch zu falschen Schlussfolgerungen führen. Daher ist es entscheidend, sich dieser typischen Fallstricke bewusst zu sein und entsprechend vorsichtig bei der Analyse vorzugehen.
Missachtung der Annahmen
Ein häufiger Fehler besteht darin, die grundlegenden Annahmen der linearen Regression nicht zu überprüfen. Diese Annahmen umfassen:
- Linearität: Es wird vorausgesetzt, dass eine lineare Beziehung zwischen den unabhängigen und abhängigen Variablen besteht.
- Homoskedastizität: Die Varianz der Fehler sollte konstant sein.
- Unabhängigkeit: Die Beobachtungen sollten unabhängig voneinander sein.
Wenn diese Bedingungen nicht erfüllt sind, kann das Modell ungenaue Vorhersagen liefern.
Überanpassung des Modells
Ein weiterer häufiger Fehler ist die Überanpassung (Overfitting). Dies tritt auf, wenn ein Modell so komplex ist, dass es nicht nur die zugrunde liegende Beziehung erfasst, sondern auch das Rauschen in den Daten lernt. Dies führt dazu, dass das Modell zwar bei den Trainingsdaten sehr gute Ergebnisse erzielt, jedoch bei neuen oder Testdaten schlecht abschneidet. Um dies zu vermeiden:
- Verwenden wir Techniken wie Kreuzvalidierung.
- Reduzieren wir die Anzahl der Prädiktoren oder setzen Regularisierungsansätze ein.
Vernachlässigung von Ausreißern
Ausreißer können einen erheblichen Einfluss auf unsere Modelle haben. Wenn extreme Werte in unseren Daten vorhanden sind und wir sie ignorieren oder nicht angemessen behandeln, können sie unsere Koeffizienten stark verzerren und somit zu falschen Interpretationen führen. Wir sollten daher:
- Ausreißer identifizieren und analysieren.
- Strategien zur Behandlung dieser Datenpunkte entwickeln.
Diese typischen Fehler verdeutlichen die Bedeutung einer sorgfältigen Vorgehensweise bei der Anwendung von Regressionsmodellen sowie das Verständnis für deren Limitationen im Kontext unserer Analysen zur linearen regression beispiel. Indem wir uns dieser Herausforderungen bewusst sind und geeignete Maßnahmen ergreifen, können wir qualitativ hochwertigere Analysen durchführen und präzisere Entscheidungen treffen.