In der heutigen digitalen Welt begegnen wir täglich Technologien, die auf Deep Learning basieren. Was ist Deep Learning und wie hat es unsere Art zu arbeiten und zu leben revolutioniert? In diesem Artikel tauchen wir gemeinsam in die faszinierende Welt des maschinellen Lernens ein und entdecken die Grundlagen sowie die Funktionsweise dieser innovativen Technik.
Wir werden untersuchen, wie Deep Learning es Maschinen ermöglicht, aus großen Datenmengen zu lernen und eigenständig Entscheidungen zu treffen. Dabei zeigen wir auf, welche Rolle neuronale Netze spielen und warum sie so entscheidend für den Erfolg von Anwendungen wie Sprach- oder Bilderkennung sind.
Haben Sie sich jemals gefragt, wie selbstfahrende Autos oder intelligente Assistenten funktionieren? Lassen Sie uns zusammen herausfinden, was hinter diesen beeindruckenden Technologien steckt und welche Potenziale Deep Learning für unsere Zukunft bereithält!
Was ist Deep Learning und welche Anwendungsgebiete gibt es
Deep Learning ist ein Teilbereich des maschinellen Lernens, der sich mit dem Training von Modellen auf der Grundlage großer Datenmengen beschäftigt. Diese Technologie hat in den letzten Jahren an Bedeutung gewonnen und findet Anwendung in vielseitigen Bereichen. Die Fähigkeit von Deep-Learning-Modellen, Muster und Zusammenhänge aus unstrukturierten Daten zu erkennen, eröffnet zahlreiche Möglichkeiten für innovative Lösungen.
Anwendungsgebiete von Deep Learning
Die Einsatzmöglichkeiten von Deep Learning sind vielfältig und erstrecken sich über verschiedene Branchen. Zu den wichtigsten Anwendungsgebieten gehören:
- Bildverarbeitung: Hier wird Deep Learning zur Erkennung und Klassifizierung von Bildern verwendet, beispielsweise in der medizinischen Bilddiagnostik oder bei autonomen Fahrzeugen.
- Spracherkennung: Technologien wie Sprachassistenten nutzen Deep Learning, um gesprochene Sprache zu verstehen und in Text umzuwandeln.
- Natursprachliche Verarbeitung (NLP): Anwendungen im Bereich NLP umfassen Übersetzungsdienste und Chatbots, die mithilfe von Deep-Learning-Techniken entwickelt werden.
- Empfehlungssysteme: Plattformen wie Netflix oder Amazon verwenden Deep Learning, um personalisierte Empfehlungen basierend auf Benutzerverhalten zu generieren.
Weitere Beispiele
Zusätzlich zu den genannten Bereichen gibt es spezielle Anwendungen in der Finanzwelt, etwa zur Betrugserkennung oder im algorithmischen Handel. In der Industrie können Wartungsprozesse durch prädiktive Analysen optimiert werden. Auch im Bereich der Kunst kommt es zum Einsatz; Künstlerische Kreationen werden mit Hilfe von Algorithmen erstellt.
Insgesamt zeigt sich, dass Deep Learning eine Schlüsseltechnologie darstellt, die nicht nur bestehende Prozesse revolutioniert, sondern auch völlig neue Ansätze ermöglicht.
Die Grundlagen von neuronalen Netzen im Deep Learning
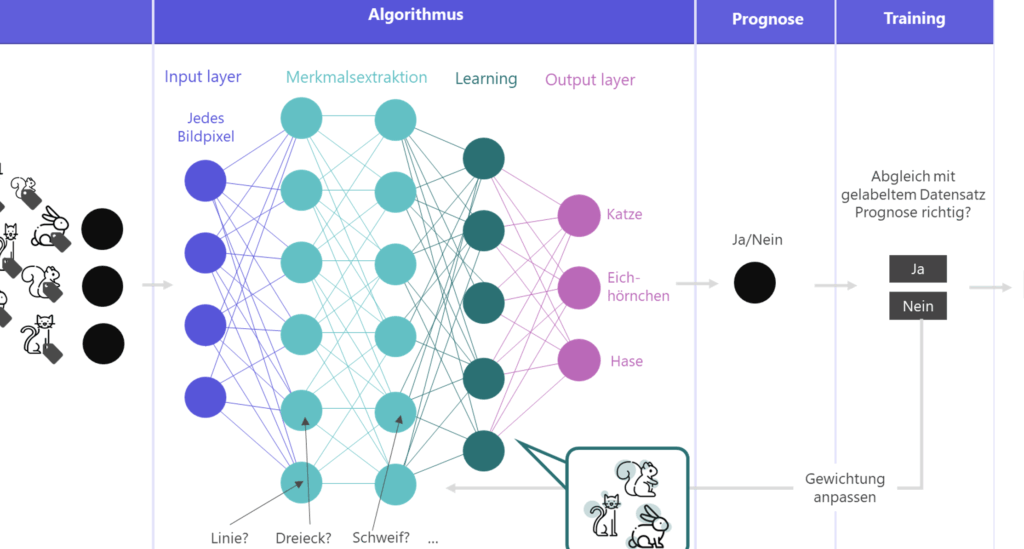
Neuronale Netze bilden das Rückgrat von Deep Learning und sind entscheidend für die Verarbeitung komplexer Datenstrukturen. Diese Modelle sind inspiriert von der Funktionsweise des menschlichen Gehirns, wobei sie aus miteinander verbundenen Knoten oder „Neuronen“ bestehen. Jedes Neuron empfängt Eingaben, verarbeitet diese durch eine Aktivierungsfunktion und gibt ein Ergebnis an die nächsten Neuronen weiter. Durch diesen Prozess kann das Netzwerk Muster in den Daten erkennen und lernen.
Ein typisches neuronales Netz besteht aus mehreren Schichten: der Eingabeschicht, einer oder mehreren versteckten Schichten und der Ausgabeschicht. Die Anzahl der Neuronen in jeder Schicht sowie die Anzahl der Schichten beeinflussen maßgeblich die Fähigkeit des Modells, Informationen zu verarbeiten.
Struktur eines neuronalen Netzes
Die grundlegende Architektur eines neuronalen Netzes lässt sich wie folgt beschreiben:
- Eingabeschicht: Hier werden die Rohdaten eingespeist.
- Versteckte Schichten: Diese führen die Berechnungen durch; je mehr Schichten vorhanden sind, desto tiefer ist das Lernen.
- Ausgabeschicht: Sie liefert das Endergebnis oder die Vorhersage basierend auf den vorhergehenden Berechnungen.
Lernprozess
Der Lernprozess erfolgt über einen Mechanismus namens Backpropagation. Dabei wird zunächst eine Vorhersage erzeugt und mit dem tatsächlichen Ergebnis verglichen. Der Fehler wird dann zurück durch das Netzwerk propagiert, um Anpassungen an den Gewichten vorzunehmen, was letztendlich dazu führt, dass das Modell besser lernt.
| Layer-Typ | Funktion |
|---|---|
| Eingabeschicht | Empfang von Rohdaten |
| Versteckte Schichten | Durchführung komplexer Berechnungen |
| Ausgabeschicht | Erzeugung des Ergebnisses oder der Vorhersage |
Die Flexibilität und Skalierbarkeit von neuronalen Netzen machen sie ideal für eine Vielzahl von Anwendungen im Bereich Deep Learning. Vom Bildverständnis bis hin zur Sprachverarbeitung können diese Netzwerke extrem präzise Ergebnisse liefern, was ihre Anwendung in vielen modernen Technologien ermöglicht.
Wie funktioniert das Training von Deep Learning Modellen
Das Training von Deep Learning Modellen ist ein komplexer Prozess, der darauf abzielt, die Gewichte und Biases in neuronalen Netzen so anzupassen, dass sie Muster in den Daten erkennen können. Dieser Vorgang erfolgt typischerweise über große Datenmengen und erfordert effektive Algorithmen sowie leistungsstarke Hardware. Der gesamte Trainingsprozess kann in mehrere Schritte unterteilt werden, die zusammenarbeiten, um ein präzises Modell zu entwickeln.
Datenaufbereitung
Bevor das Training beginnen kann, müssen die Rohdaten entsprechend vorbereitet werden. Dies umfasst verschiedene Schritte wie:
- Datenbereinigung: Entfernen von Rauschen und irrelevanten Informationen.
- Datennormalisierung: Skalierung der Werte auf einen bestimmten Bereich zur Verbesserung der Konvergenzgeschwindigkeit.
- Trainings-, Validierungs- und Testdatensätze: Aufteilen der Daten in diese Gruppen stellt sicher, dass das Modell nicht nur gut lernt, sondern auch auf neuen Daten generalisieren kann.
Forward Propagation und Backpropagation
Sobald die Daten bereit sind, wird das Modell durch Forward Propagation trainiert. Dabei werden Eingabewerte durch die Schichten des neuronalen Netzes geleitet:
- Zuerst berechnet jedes Neuron seinen Aktivierungswert basierend auf den Eingaben und den aktuellen Gewichten.
- Anschließend wird eine Vorhersage für die Ausgabeschicht generiert.
Um das Modell zu optimieren, kommt Backpropagation ins Spiel. Hierbei geschieht Folgendes:
| Schritt | Beschreibung |
|---|---|
| Error Berechnung | Der Unterschied zwischen Vorhersage und tatsächlichem Wert wird ermittelt. |
| Korrektur der Gewichte | Anpassungen an den Gewichten erfolgen anhand des Fehlers mit Hilfe von Gradientenabstieg. |
| Iterativer Prozess | Dieser Vorgang wiederholt sich über viele Epochen hinweg bis zur Erreichung einer akzeptablen Genauigkeit. |
Durch diesen iterativen Lernprozess verbessert das Netzwerk kontinuierlich seine Fähigkeit zur Mustererkennung. Die Wahl geeigneter Hyperparameter wie Lernrate oder Anzahl der Epochen spielt ebenfalls eine entscheidende Rolle dabei, wie schnell und effektiv das Modell lernt. Letztendlich führt dieses strukturierte Vorgehen dazu, dass Deep Learning Modelle präzise Vorhersagen treffen können und somit in vielfältigen Anwendungsbereichen eingesetzt werden können.
Zukünftige Entwicklungen und Trends im Bereich Deep Learning
Die Entwicklungen im Bereich Deep Learning schreiten rasant voran. Wir beobachten, dass Technologien und Methoden sich ständig weiterentwickeln, um den wachsenden Anforderungen an Effizienz und Effektivität gerecht zu werden. Dabei sind verschiedene Trends erkennbar, die nicht nur die Technik selbst betreffen, sondern auch deren Anwendung in der Praxis.
Ein herausragender Trend ist der Einsatz von Transfer Learning, bei dem ein bereits trainiertes Modell für neue Aufgaben genutzt wird. Dies reduziert den Aufwand für das Training erheblich und ermöglicht es uns, Modelle schneller anzupassen. Zudem gewinnt die Interpretierbarkeit von Modellen zunehmend an Bedeutung. In vielen Anwendungen ist es notwendig, nachvollziehen zu können, wie Entscheidungen getroffen werden. Fortgeschrittene Techniken zur Visualisierung von neuronalen Netzen helfen dabei, diese Transparenz zu schaffen.
Automatisierung des Machine Learning
Ein weiterer Schlüsseltrend ist die Automatisierung im Bereich Machine Learning (AutoML). Hierbei geht es darum, Prozesse wie Hyperparameteroptimierung oder Modellwahl durch Algorithmen automatisiert durchführen zu lassen. Dadurch sparen wir Zeit und können Ressourcen effizienter einsetzen. Wichtige Aspekte dieser Automatisierung umfassen:
- Modellauswahl: Algorithmen entscheiden automatisch über das beste Modell basierend auf den gegebenen Daten.
- Hyperparameteroptimierung: Durch automatisierte Verfahren wird die Suche nach optimalen Parametern stark beschleunigt.
- Feature Engineering: Auch hier kommen intelligente Systeme zum Einsatz, um relevante Merkmale aus den Daten abzuleiten.
Integration von Edge Computing
Darüber hinaus sehen wir eine zunehmende Integration von Deep Learning mit Edge Computing-Technologien. Diese Kombination ermöglicht es uns, komplexe Berechnungen näher am Ort der Datenerfassung durchzuführen. Vorteile hiervan sind:
- Geringere Latenzzeiten, da weniger Daten zur zentralen Cloud gesendet werden müssen.
- Erhöhte Sicherheit, da sensible Informationen lokal verarbeitet bleiben.
- Ressourcenschonung, weil weniger Bandbreite benötigt wird.
Die Fortschritte in diesen Bereichen deuten darauf hin, dass Deep Learning nicht nur weiterhin eine zentrale Rolle in der KI spielen wird, sondern auch zunehmend zugänglicher und praktikabler für verschiedene Branchen wird.